# JVM入门与进阶
# 简介JVM
一个基于栈的Java虚拟机
JVM是一个任何参数都提供了默认值的虚拟机
# Java的核心优势
- 生态完善
- 非常好的跨平台语言
- 有自己的虚拟机和垃圾回收器(能很好的管理内存)
# Java是如何运行的(简化)
.java文件编译生成.class文件,也就是Java字节码文件,java运行时将字节码文件通过类加载器加载到jvm中并在内存中生成对象实例。
# JVM参数的设置
《JVM参数》
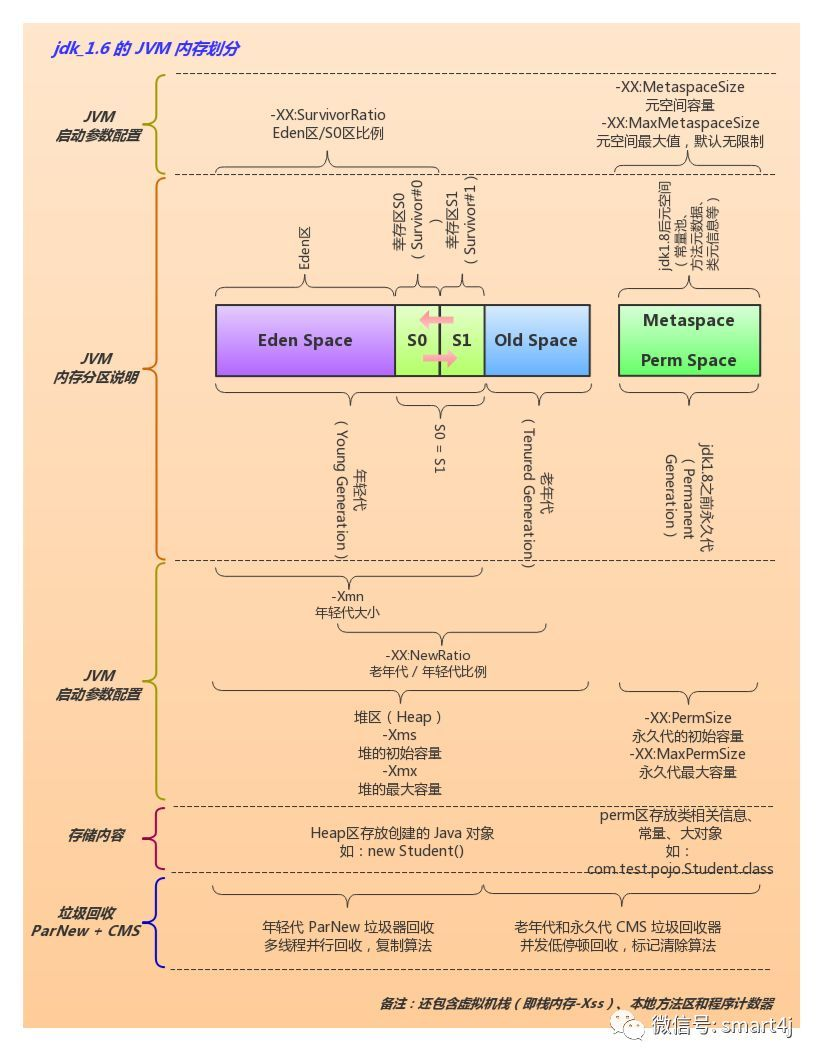
# JVM内存分布
# 垃圾收集算法
# 如何判断对象需要回收
# 分代收集理论
# 标记-清除
# 标记-复制
# 标记-整理
# HotSpot的垃圾收集器(GC)
以下是7种HotSpot GC的搭配关系图:
有不需要STW的垃圾收集器吗?
通常用哪些指标衡量垃圾收集器?
# Serial收集器
工作机制是什么(什么算法实现、和其他收集器的组合有什么)?是指单线程吗?单线程是垃圾收集线程只有一个吗?
现在还有使用它的场景吗?
觉得它基本没有使用的场景,那你说下它的优缺点吧。
# ParNew收集器
工作机制?什么算法实现?
什么时候使用?
与Serial收集器相比如何?
# Parallel Scavenge收集器
工作机制及算法实现是什么?
与ParNew的区别是什么?
为什么它常被称作“吞吐量优先收集器”?
使用它常设置哪些JVM参数?
# Serial Old收集器
工作机制和内容分别是什么?
# Parallel Old收集器
工作机制和内容分别是什么?
怎么组合使用?
# CMS收集器
工作机制是什么?(有四个步骤,你知道是哪些吗?)
什么时候会触发STW?什么时候不需要STW?
它有哪些优缺点?
JDK9已经不推荐使用CMS收集器了。
# G1收集器
JDK9发布之后,G1取代Parallel Scavenge+Parallel Old组合,成为服务端模式下默认收集器。
G1 GC是启发式算法,会动态调整年轻代的空间大小。目标也就是为了达到接近预期的暂停时间。G1提供了两种GC模式,Young GC和Mixed GC,两种都是Stop The World(STW)的。
# G1的结构
G1抛弃了之前的分代收集的方式,面向整个堆内存进行回收,把内存划分为多个大小相等的独立区域Region。
一共有4种Region:
- 自由分区Free Region
- 年轻代分区Young Region,年轻代还是会存在Eden和Survivor的区分
- 老年代分区Old Region
- 大对象分区Humongous Region
每个Region的大小通过-XX:G1HeapRegionSize来设置,大小为1~32MB,默认最多可以有2048个Region,那么按照默认值计算G1能管理的最大内存就是32MB*2048=64G。
对于大对象的存储,存在Humongous概念,对G1来说,超过一个Region一半大小的对象都被认为大对象,将会被放入Humongous Region,而对于超过整个Region的大对象,则用几个连续的Humongous来存储。
# G1的优点
垃圾收集器的目的是减少STW造成的停顿。
G1最大的优势是可预测的停顿时间模型,通过参数-XX:MaxGCPauseMillis设置(默认200ms)。
G1会收集每个Region的回收之后的空间大小、回收需要的时间,根据评估得到的价值,维护一个优先级列表,基于我们设置的停顿时间,优先回收价值收益最大的Region。
# G1步骤
- 初始标记:标记GC Roots能关联到的对象
- 并发标记:从GC Roots直接关联的对象开始遍历整个对象图
- 最终标记:暂停用户线程,再处理一次
- 筛选回收:更新Region的统计数据,根据用户设置的停顿时间制定回收计划,把需要回收的Region中存活的对象复制到空的Region,清理旧的Region
以上只有第二步并发标记不需要STW。
# 记忆集
G1的记忆集相对复杂,每个Region中都存在一个Hash Table结构的记忆集,Key为其他Region的起始地址,Value是其他Card Table卡表的索引集合。
维护记忆集的方式也是写屏障。
# 并发标记对象消失
G1使用原始快照的方式解决并发标记的对象消失问题。
# G1的参数
# -XX:MaxGCPauseMillis
暂停时间,默认值200ms。这是一个软性目标,G1会尽量达成,如果达不成,会逐渐做自我调整。
对于Young GC来说,会逐渐减少Eden区个数,减少Eden空间那么Young GC的处理时间就会相应减少。对于Mixed GC,G1会调整每次Choose Cset的比例,默认最大值是10%,当然每次选择的Cset少了,所要经历的Mixed GC的次数会相应增加。
减少Eden的总空间时,就会更加频繁的触发Young GC,也就是会加快Mixed GC的执行频率,因为Mixed GC是由Young GC触发的,或者说借机同时执行的。频繁GC会对对应用的吞吐量造成影响,每次Mixed GC回收时间太短,回收的垃圾量太少,可能最后GC的垃圾清理速度赶不上应用产生的速度,那么可能会造成串行的Full GC,这是要极力避免的。所以暂停时间肯定不是设置的越小越好,当然也不能设置的偏大,转而指望G1自己会尽快的处理,这样可能会导致一次全部并发标记后触发的Mixed GC次数变少,但每次的时间变长,STW时间变长,对应用的影响更加明显。
# -XX:G1HeapRegionSize
Region大小,若未指定则默认最多生成2048块,每块的大小需要为2的幂次方,如1,2,4,8,16,32,最大值为32M。Region的大小主要是关系到Humongous Object的判定,当一个对象超过Region大小的一半时,则为巨型对象,那么其会至少独占一个Region,如果一个放不下,会占用连续的多个Region。当一个Humongous Region放入了一个巨型对象,可能还有不少剩余空间,但是不能用于存放其他对象,这些空间就浪费了。所以如果应用里有很多大小差不多的巨型对象,可以适当调整Region的大小,尽量让他们以普通对象的形式分配,合理利用Region空间。
# -XX:G1NewSizePercent和-XX:G1MaxNewSizePercent
新生代比例有两个数值指定,下限:-XX:G1NewSizePercent,默认值5%,上限:-XX:G1MaxNewSizePercent,默认值60%。G1会根据实际的GC情况(主要是暂停时间)来动态的调整新生代的大小,主要是Eden Region的个数。最好是Eden的空间大一点,毕竟Young GC的频率更大,大的Eden空间能够降低Young GC的发生次数。但是Mixed GC是伴随着Young GC一起的,如果暂停时间短,那么需要更加频繁的Young GC,同时也需要平衡好Mixed GC中新生代和老年代的Region,因为新生代的所有Region都会被回收,如果Eden很大,那么留给老年代回收空间就不多了,最后可能会导致Full GC。
# -XX:ConcGCThreads
通过 -XX:ConcGCThreads来指定并发GC线程数,默认是-XX:ParallelGCThreads/4,也就是在非STW期间的GC工作线程数,当然其他的线程很多工作在应用上。当并发周期时间过长时,可以尝试调大GC工作线程数,但是这也意味着此期间应用所占的线程数减少,会对吞吐量有一定影响。
ConcGCThreads = (3 + ParallelGCThreads) / 4
# -XX:ParallelGCThreads
通过-XX:ParallelGCThreads来指定并行GC线程数,也就是在STW阶段工作的GC线程数,其值遵循以下原则:
如果用户显示指定了ParallelGCThreads,则使用用户指定的值。否则需要根据实际的CPU所能够支持的线程数来计算ParallelGCThreads的值。如果物理CPU所能够支持线程数小于8,则ParallelGCThreads的值为CPU所支持的线程数。这里的阀值为8,是因为JVM中调用nof_parallel_worker_threads接口所传入的switch_pt的值均为8。如果物理CPU所能够支持线程数大于8,则ParallelGCThreads的值为8加上一个调整值,调整值的计算方式为:物理CPU所支持的线程数减去8所得值的5/8或者5/16,JVM会根据实际的情况来选择具体是乘以5/8还是5/16。ParallelGCThreads= 8 + (N - 8) * 5 / 8 比如,在64线程的x86 CPU上,如果用户未指定ParallelGCThreads的值,则默认的计算方式为:ParallelGCThreads = 8 + (64 - 8) * (5/8) = 8 + 35 = 43。
# -XX:G1MixedGCLiveThresholdPercent
通过这个参数指定被纳入Cset的Region的存活空间占比阈值,不同版本默认值不同,有65%和85%。在全局并发标记阶段,如果一个Region的存活对象的空间占比低于此值,则会被纳入Cset。此值直接影响到Mixed GC选择回收的区域,当发现GC时间较长时,可以尝试调低此阈值,尽量优先选择回收垃圾占比高的Region,但此举也可能导致垃圾回收的不够彻底,最终触发Full GC。
# -XX:InitiatingHeapOccupancyPercent
通过这个参数指定触发全局并发标记的老年代使用占比,默认值45%,也就是老年代占堆的比例超过45%。如果Mixed GC周期结束后老年代使用率还是超过45%,那么会再次触发全局并发标记过程,这样就会导致频繁的老年代GC,影响应用吞吐量。同时老年代空间不大,Mixed GC回收的空间肯定是偏少的。可以适当调高IHOP的值,当然如果此值太高,很容易导致年轻代晋升失败而触发Full GC,所以需要多次调整测试。
# -XX:G1HeapWastePercent
通过这个参数指定触发Mixed GC的堆垃圾占比,默认值5%,也就是在全局标记结束后能够统计出所有Cset内可被回收的垃圾占整对的比例值,如果超过5%,那么就会触发之后的多轮Mixed GC,如果不超过,那么会在之后的某次Young GC中重新执行全局并发标记。可以尝试适当的调高此阈值,能够适当的降低Mixed GC的频率。
# -XX:G1OldCSetRegionThresholdPercent
通过这个参数指定每轮Mixed GC回收的Region最大比例,默认10%,也就是每轮Mixed GC附加的Cset的Region不超过全部Region的10%,最多10%,如果暂停时间短,那么可能会少于10%。一般这个值不需要额外调整。
# -XX:G1MixedGCCountTarget
通过这个参数指定一个周期内触发Mixed GC最大次数,默认值8。一次全局并发标记后,最多接着8次Mixed GC,把全局并发标记阶段生成的Cset里的Region拆分为最多8部分,然后在每轮Mixed GC里收集一部分。这个值要和上一个参数配合使用,8*10%=80%,应该来说会大于每次标记阶段的Cset集合了。一般此参数也不需额外调整。
# -XX:G1ReservePercent
通过这个参数指定G1为分配担保预留的空间比例,默认10%。也就是老年代会预留10%的空间来给新生代的对象晋升,如果经常发生新生代晋升失败而导致Full GC,那么可以适当调高此阈值。但是调高此值同时也意味着降低了老年代的实际可用空间。
# -XX:MaxTenuringThreshold
晋升年龄阈值,默认值15。一般新生对象经过15次Young GC会晋升到老年代,巨型对象会直接分配在老年代,同时在Young GC时,如果相同age的对象占Survivors空间的比例超过 -XX:TargetSurvivorRatio的值(默认50%),则会自动将此次晋升年龄阈值设置为此age的值,所有年龄超过此值的对象都会被晋升到老年代,此举可能会导致老年代需要不少空间应对此种晋升。一般这个值不需要额外调整。
# 调优建议
不要手动设置新生代和老年代的大小,只设置这个堆的大小 G1收集器在运行过程中,会自己调整新生代和老年代的大小 其实是通过adapt代的大小来调整对象晋升的速度和年龄,从而达到为收集器设置的暂停时间目标, 如果手动设置了大小就意味着放弃了G1的自动调优。
不断调优暂停时间目标-XX:MaxGCPauseMillis,一般情况下这个值设置到100ms或者200ms, 暂停时间设置的太短,就会导致出现G1跟不上垃圾产生的速度。最终退化成Full GC。所以对这个参数的调优是一个持续的过程,逐步调整到最佳状态。暂停时间只是一个目标,并不能总是得到满足。
# Shenandoah收集器
# ZGC收集器
# Epsilon收集器
# 解析GC日志
《GC日志专题》
# JVM工具
《JVM工具》
# 字节码文件(Class文件)
《字节码Class文件》
# JMM
JMM是什么?与JVM的关系是什么?介绍下JMM。 JMM中定义了哪些Action? 把变量从主内存复制到工作内存需要执行哪些action? 把变量从工作内存同步回主内存需要执行哪些action? JMM的三大特性? JMM提供的happends-before规则是什么? happends-before是依靠什么来保障的呢?
你可以认为JMM是JVM 的数据存储模型,它是一个抽象的概念。 JMM分为主存储器(Main Memory)和工作存储器(Working Memory)。 主存储器是实例位置所在的区域,所有的实例都存在于主存储器内。比如,实例所拥有的字段即位于主存储器内,主存储器是所有的线程所共享的。 工作存储器是线程所拥有的作业区,每个线程都有其专用的工作存储器。工作存储器存有主存储器中必要部分的拷贝,称之为工作拷贝(Working Copy)。 在JMM中,线程无法对主存储器直接进行操作。 如果你非要将这两存储器对应到内存中的区域,可以这样看,主存通常是Java堆(其实也可能是高速缓存或CPU寄存器),工作内存对应虚拟机栈(也可能是硬件内存),不用太纠结位置。 JMM中定义了8个Action: 1.read(读取) 2.load(载入) 3.store(存储) 4.write(写入) 5.use(使用) 6.assign(赋值) 7.lock(锁定) 8.unlock(解锁) 把一个变量从主内存复制到工作内存中,需要顺序执行read和load,把变量从工作内存同步回主内存,需要顺序执行store和write操作。 JMM的三大特性:1.原子性 2.可见性 3.有序性 JMM提供的happends-before规则: 1.程序次序 2.监视器锁定 3.volatile 4.传递规则 5.线程启动 6.线程中断 7.线程终结规则 8.对象终结规则 happends-before是依靠什么来保障的呢:内存屏障。
# 内存屏障有哪些组合?
- Load-Load Barriers
- Load-Store Barriers
- Store-Store Barriers
- Store-Load Barriers
# 指令操作码(opcode)
根据指令的性质,最多分为四个大类:
# 类的生命周期
# 类的加载时机
# 对象内存计算
# Q&A
# JVM通常会遇到哪些突如其来的棘手问题?
1.GC时间过长 2.发生OOM
# 字节码的偏移量多出来的位置为什么要补00?
# java8默认使用的GC算法是什么?
# 如何切换JVM垃圾收集器?
# 什么时候会发生OOM,一般都是由什么导致的?
# 当发生OOM时如何定位问题?
使用MAT定位
使用 MAT 分析 OOM 问题 (opens new window)
- 生产环境一般要配置OOM堆转储的JVM参数
-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=.
# G1 GC的1的意思是什么?有了解过吗?
# 如何排查CPU高,程序响应慢的问题
- top命令获取占用CPU最高的程序PID
$ top
- 找到此进程中消耗CPU较高的线程ID
$ top -Hp {pid} 可以根据top命令显示的TIME+列(消耗CPU时间),找到消耗时间最长的线程ID
- 将线程ID转换为16进制
$ printf "%x\n" {pid}
- 使用jstack打印堆栈信息,可以在log文件中搜索到nid(本地线程标识)的16进制,定位代码问题即可。
$ jstack -l {pid} > stack.log